Rapid GraphQL API Development with PostGraphile
Guiding Principles in API Development
More and more companies are adopting a microservices architecture for developing scalable software systems. Such architectures rely on well-defined APIs to offer the agility and scalability that it promises. However, many of the systems of today are data-driven and revolve around basic CRUD operations. These operations are tedious to manually implement and maintain, eating into developer time better spent on functionalities of business value.
Axinom has a wealth of expertise in designing modular end-to-end content supply chain workflows based on our Axinom Mosaic platform. Built on a microservices approach, Axinom Mosaic offers a portfolio of managed and customizable services to our customers. When building our array of services and their backend APIs, we’ve focused on the following as our https://www.axinom.com/media/mosaic/quick-start-development [guiding principles].
-
Embrace the “database as an API” paradigm
To rapidly design & iterate enriched user interfaces, which result in a remarkable user experience. -
Favor auto-generation
To minimize the effort required for API CRUD operations and design rich generation templates to get the most of your data. -
Performant APIs
To consider performance to be built-in and still leaving room for specific optimizations.
Let’s take a look at the approach we took in designing our APIs.
Building the Modern API
In order to build an API that aligns with our principles, we chose GraphQL and PostGraphile. The choice of GraphQL was due to its ability to define strongly typed, scalable, and performant APIs. GraphQL cuts off the need for multiple roundtrips by allowing you to define and get precisely the data you request for, nothing more or nothing less. PostGraphile has the ability to automatically generate GraphQL schemata and matching resolvers from a PostgreSQL database schema. Also, having chosen PostgreSQL as our main flavor of database further nudged our relationship with PostGraphile. (Here is an interesting read from the team at Netflix Studio Engineering detailing how Netflix considers using PostGraphile for their GraphQL microservices.)
Schema-First vs. Code-First
Generally, GraphQL Server implementations follow either a schema-first or a code-first design.
For those who may be relatively new to GraphQL, here is a quick recap. A GraphQL API is defined using a Schema Definition Language (SDL), pretty similar to how protocol buffer message types are defined. It is programming language agnostic and has its own type system for defining data structures that the API will work against.
A hypothetical GraphQL Schema for an API which deals with movies & actors may look as below:
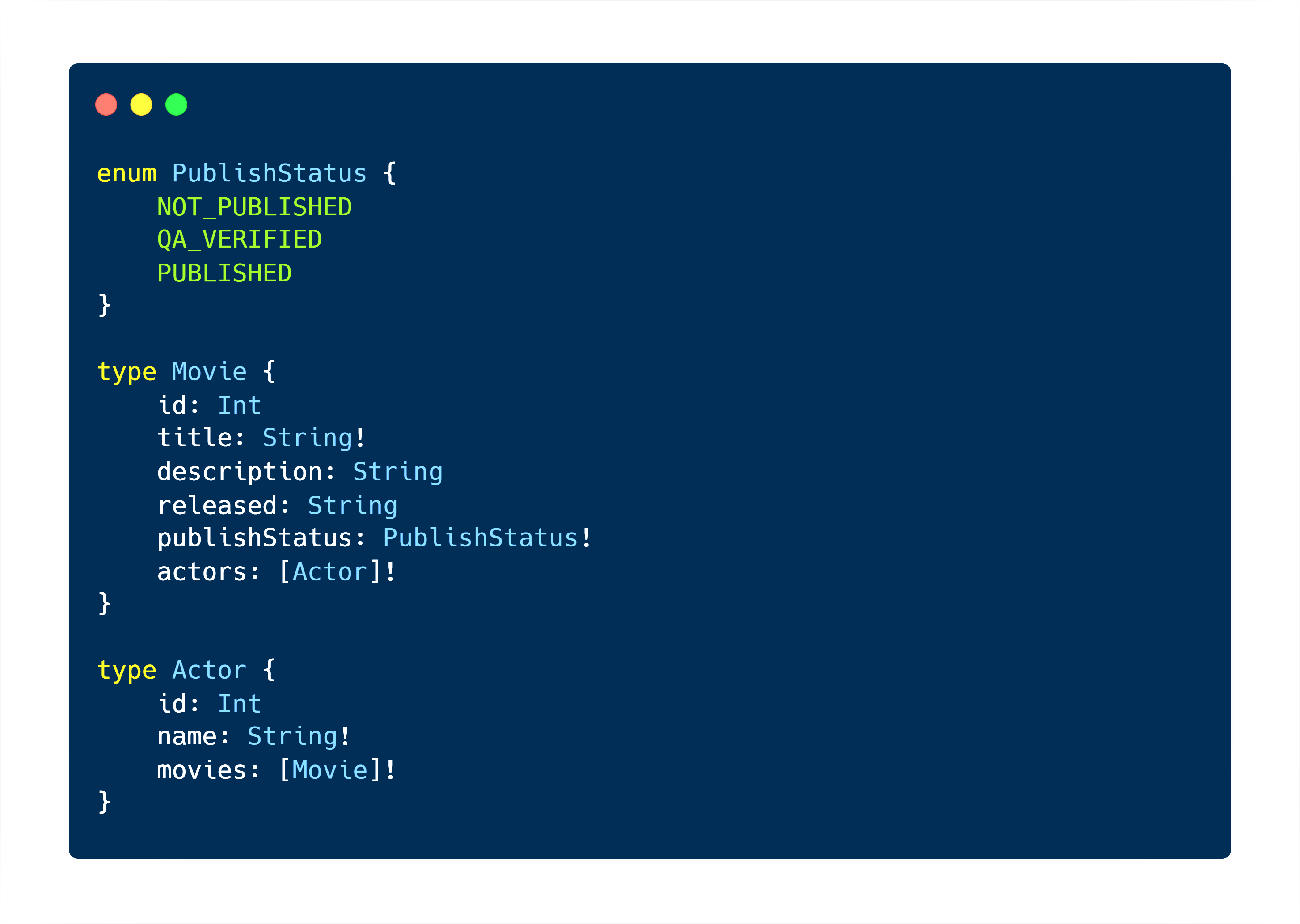
In a schema-first design, such schema definition is written first and used as input by the GraphQL server implementation. The server will parse it, and finally, resolvers (written fully decoupled) would be mapped to the fields found in the schema types. The resolvers being the actual code (written in a native language) that computes a field’s value. An example of how this decoupled approach can be used to spin up a GraphQL server is demonstrated by one of the well-known server implementations, Apollo Server.
On the other side of the spectrum, when it comes to code-first design, a native language abstraction is used instead of real schema, and the resolvers are coupled together. For example, GraphQL Nexus is a well-known library that exports strong types which could be used to represent a similar SDL along with the resolvers but in a code-first design as below:
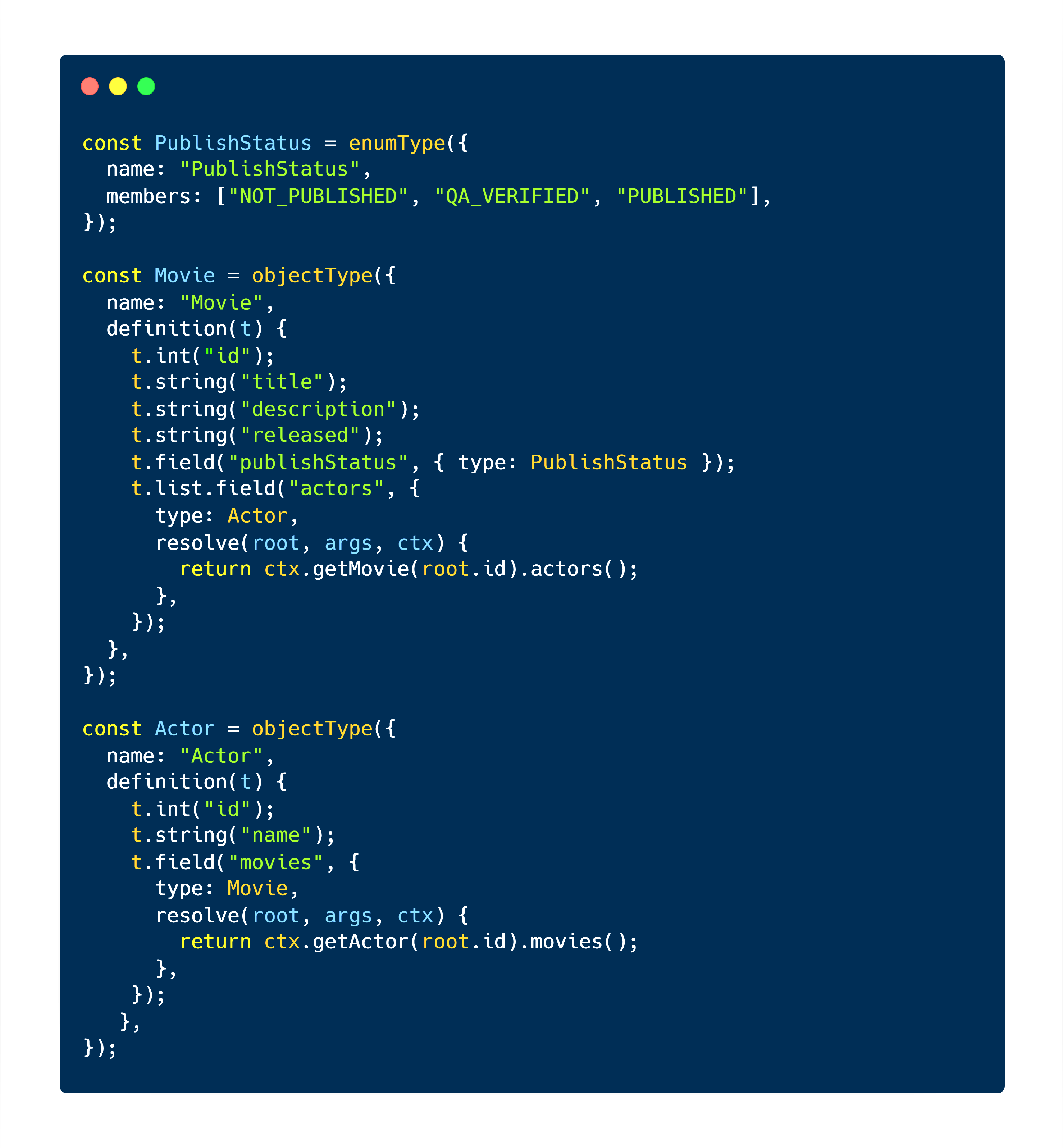
This means there will still be a GraphQL Schema, but it will be generated from a different native language abstraction.
DataBase-First Design with PostGraphile
The approach taken by PostGraphile is different, as it treats the real underlying database schema as the “source of truth.” Therefore, it generates a GraphQL Schema as well as the matching resolvers based on the database schema which we could refer to as a DataBase-First GraphQL server implementation.
We wanted to give the best reach possible to our UI/UX engineers when it comes to accessing data. Having a well-defined database schema really pays off here. PostGraphile introspects all the correct types, constraints, relations & indexes in the database schema and interprets it into an expressive GraphQL schema. This approach enables us to truly expose our database-as-an-API.
Not only generating the GraphQL schema but doing so with matching resolvers is something we now don’t want to live without. This also made perfect sense, given the majority of our use-cases of the GraphQL API are serving CRUD operations.
We find many libraries that try hard to be unopinionated (supporting multiple Object Relational Mappers, supporting multiple databases) but, in doing so, being unable to provide a fully streamlined solution. Here, PostGraphile is a prime example of doing one thing and doing that thing exceptionally well.
Extensive PostGraphile Plug-In Architecture
Since we get all of our GraphQL CRUD APIs auto-generated, we needed the APIs to be consistent and expressive to fully utilize the power of GraphQL from its consuming clients. There exists an extensive plug-in architecture built into PostGraphile, which, when used appropriately, gives your GraphQL APIs the expressiveness & the structure you desire.
Considering the sample SQL as shown below, let’s have a look at what PostGraphile would generate in terms of the GraphQL schema:
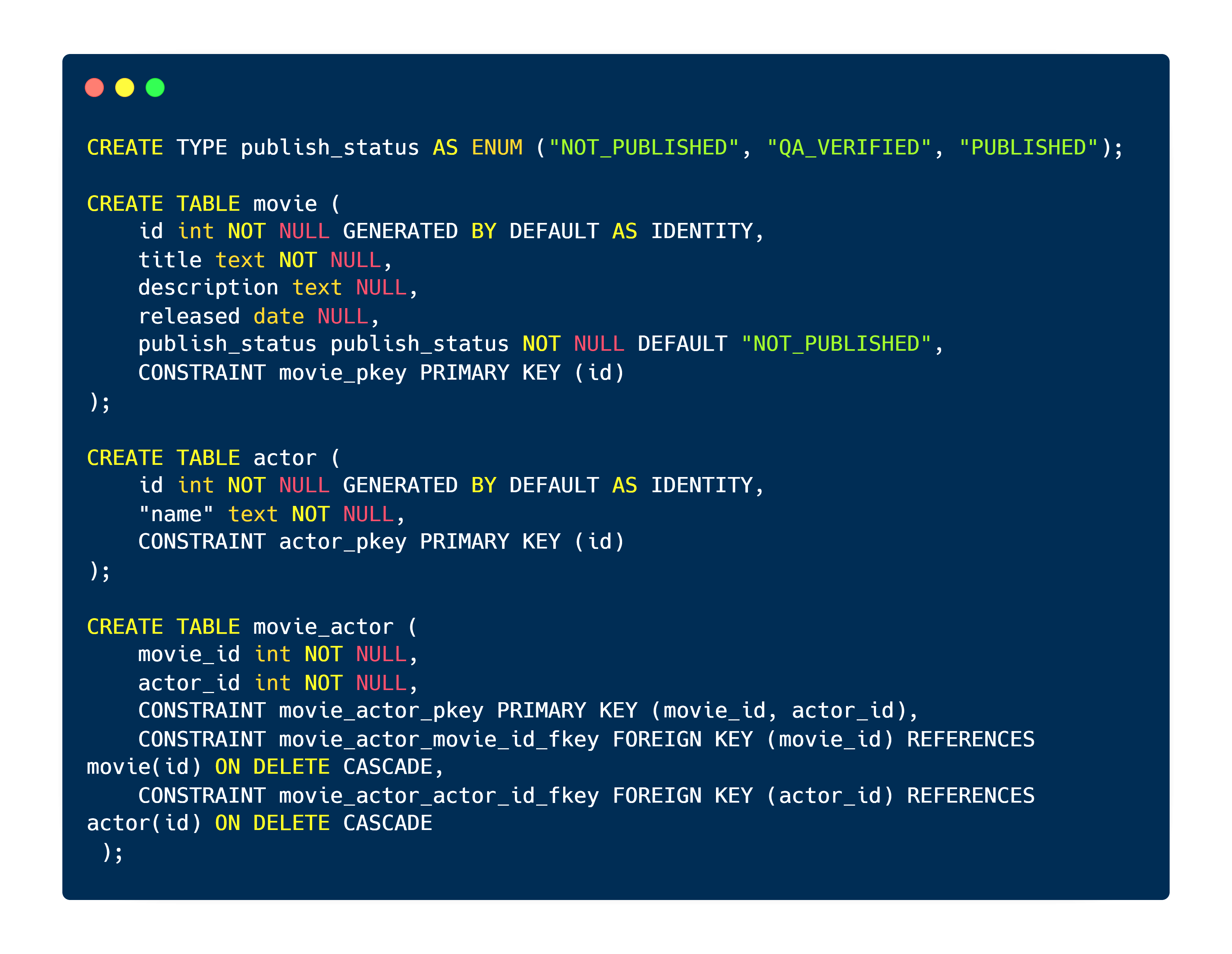
Shown below is an excerpt from the generated GraphQL schema for the actor entity. Straight off the bat, we recognize the extra work the built-in PostGraphile plug-ins have put in. It has added conditions to filter with, pagination support with cursors, sorting support, as well as an option to pick first & last N rows.
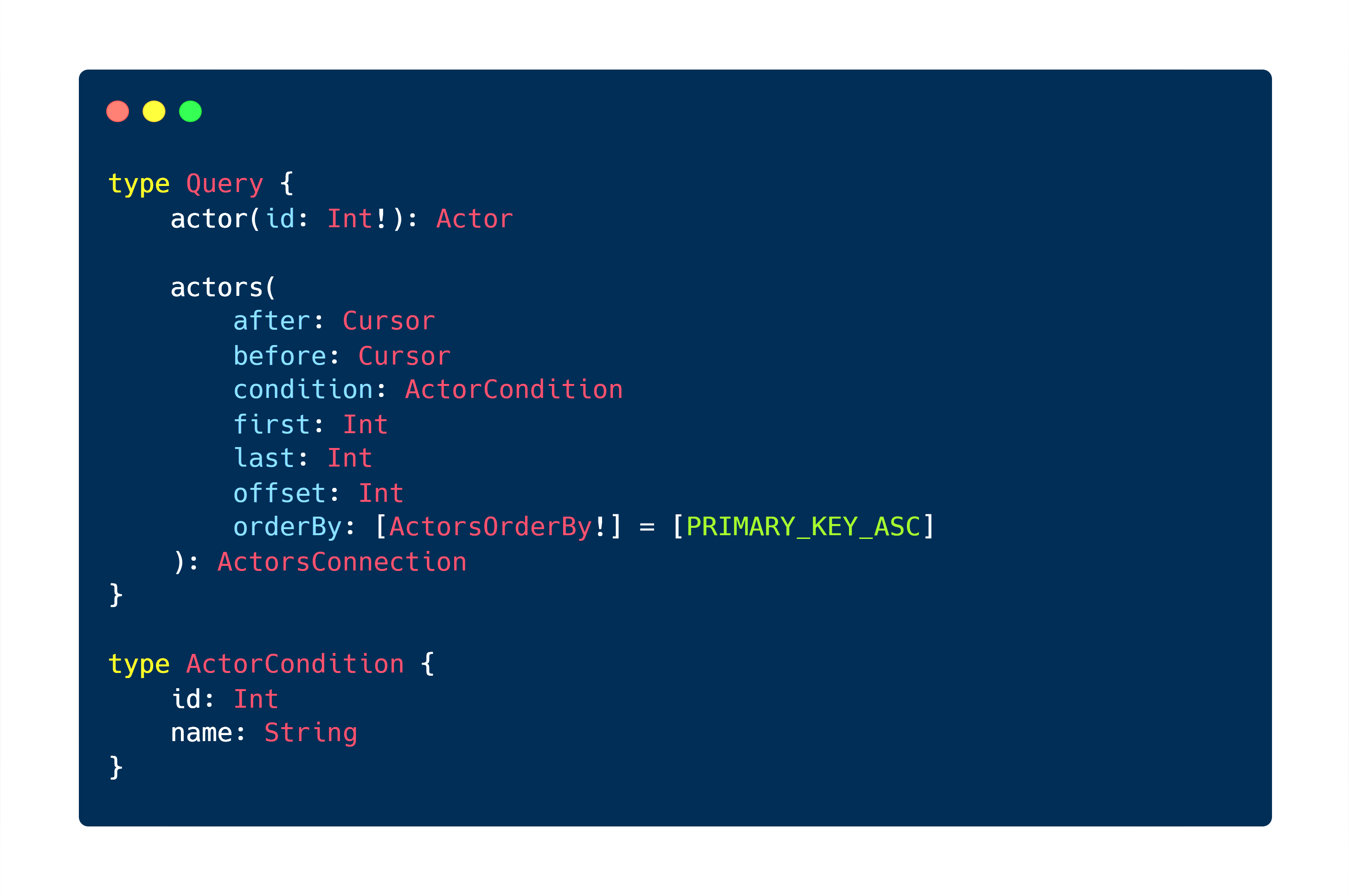
Think this is still basic, and you’d like to see more filter options which doesn’t only involve direct equations but also conditionals, ranges & partial string matches? You got it. Just install the postgraphile-plugin-connection-filter community plugin, and you’d be able to breeze away at GraphQL queries, such as:
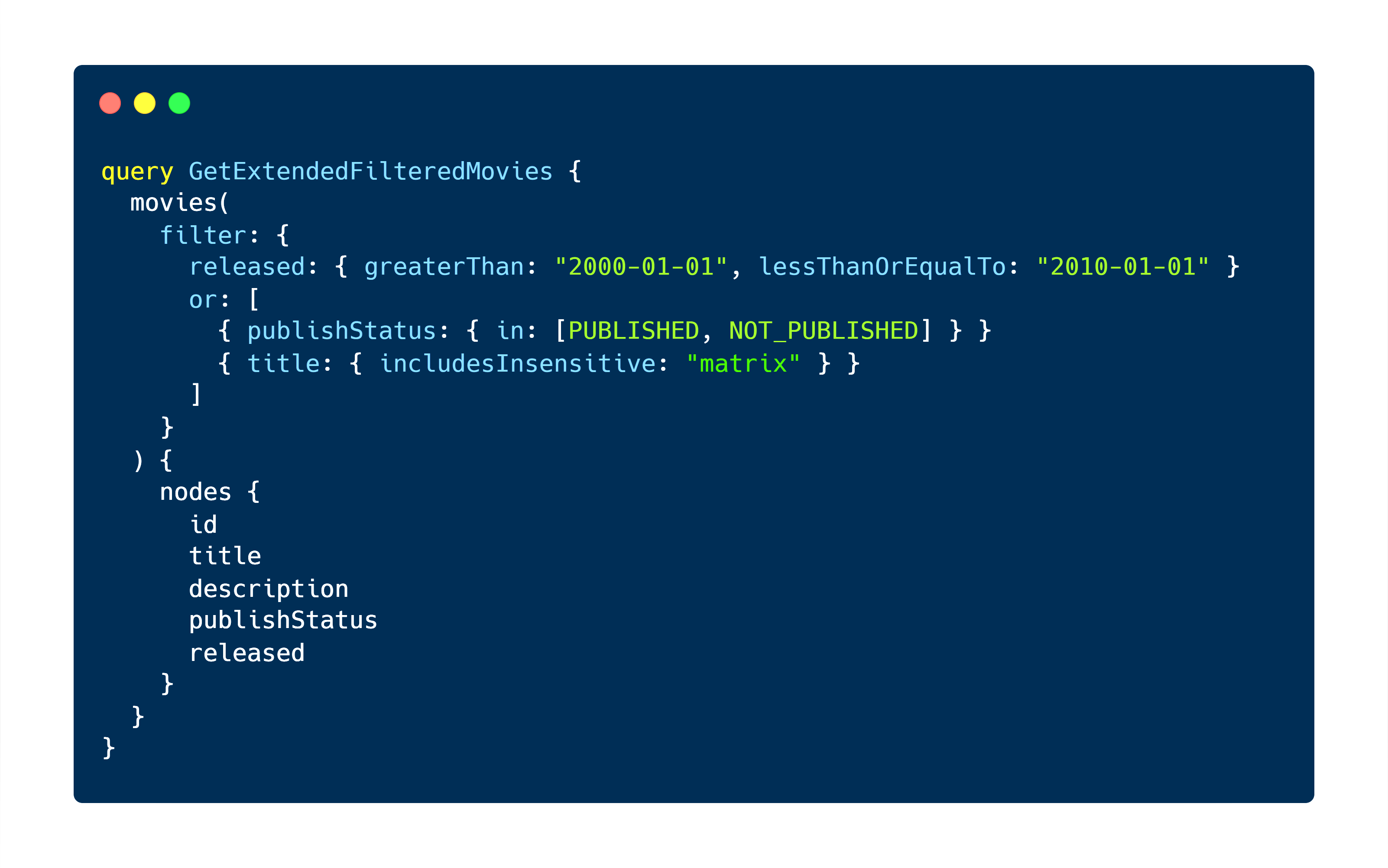
The above query returns all the movie titles released between 2000-01-01 & 2010-01-01 if either their publish status is PUBLISHED, NOT_PUBLISHED, or if the movie title has the word matrix somewhere in it (case insensitive).
If the built-in and the community-developed plugins don’t meet your requirements, it’s possible to write your own plug-ins. PostGraphile gives you several points of integration when developing plug-ins.
-
Schema-Extender plug-ins - write completely new GraphQL schema definitions, which extend the existing schema along with its resolvers.
-
Wrapper plug-ins - wrap existing resolvers with some custom code you control, where you can do something before or after the original code.
This leaves very powerful options to customize your GraphQL API to be exactly how you desire. You can leverage the benefits of automatic generation of GraphQL schema & matching resolvers for the majority of CRUD operations from your database schema to rapidly accelerate your GraphQL API development.
Ensuring Performant APIs
When designing GraphQL APIs with Schema-First and Code-First approaches, it’s very common to incorporate some Object Relational Mapper (ORM) libraries to help interface with the database. This works well enough in most cases. However, ORMs start to struggle a bit when your client queries tend to become complex. Sometimes, even seemingly innocent-looking queries may have a significant impact on performance and have the potential to go out of hand rather quickly if not attended to promptly.
The Common N+1 Problem
Let’s take a simple example of TV shows & seasons. A single TV show may have zero or more seasons. Let’s say you need to do something as simple as listing all the TV shows and their respective seasons. A simple GraphQL query as below will get the job done.

If we’ve written a naive resolver in the GraphQL server implementation using an ORM, the above query could be translated to an SQL, such as:

and then, for each TV show row, there could be another SQL, such as:

If there were N TV shows in the database, the Q2 query would run for N times, and the Q1 query would run for 1 time, giving you a total of N+1 roundtrips to the database. This is not a scalable approach. You could also imagine the exponential growth of the query performance when the number of hierarchies in the GraphQL query is increased (i.e., list all TV shows, seasons, and episodes).
To solve this performance issue when using ORMs, it’s also quite common to use some utilities called DataLoaders.
DataLoaders
Almost all implementations of DataLoaders use some form of batching and/or caching. It’ll sit in-between the GraphQL resolver and the database to intercept the request.
Let’s take the same query as above. The 'smarter' DataLoader will first get the IDs of TV shows from Q1, and rather than running individual queries for Q2, it’ll batch everything together and issue a single query using the ORM, which results in an SQL, such as:

This immediately yields better performance by reducing the N+1 roundtrips to just 1+1. However, this is not the best approach. As you’d have noticed already, the deeper the nesting hierarchy, so increases the number of queries (at least now it’s no longer data-dependant, but rather entity-dependant).
Smart Resolvers with PostGraphile
Did you ever think: why would one need to go through all that trouble to fetch such relational data, and why can’t you simply perform a table JOIN and achieve all this in a single database query, no matter the GraphQL query nesting levels? That’s exactly what PostGraphile offers. DataLoaders offer a very generic approach to a common problem, whereas PostGraphile offers an opinionated alternative. Again, doing one thing, and doing it well, offers better performance gains compared to the DataLoader solution.
When PostGraphile auto-generates the GraphQL schema & resolvers, it makes full use of the PostgreSQL relation metadata resulting in rather smart resolvers. They are capable of converting any GraphQL query request into exactly a single SQL query with JOINs. This, combined with database design best practices of having correct constraints & indexes in place, gives you an unmatched performance advantage over the other generic alternatives.
For the same example as above, PostGraphile would generate an SQL somewhat similar to:

We’ve kept the example in the simplest form to better understand the concept here, but you could easily extrapolate how this would formulate when the request GraphQL query is complex (i.e., there will be plenty more joins). So, having a good database design is the key for almost everything we discussed so far.
Conclusion
We’ve seen how PostGraphile has helped achieve our goals when designing GraphQL APIs in our Mosaic Platform. From exposing the database directly as an API, rapidly developing powerful & expressive APIs for CRUD operations, auto-generating schema & resolvers, and enforcing performance as a 1st class citizen.
If you think this sounds interesting and would like to know more about how we build our next-gen microservices, strike up a conversation with us below. Also, feel free to check out the Axinom Mosaic platform and what it has to offer to help build your video streaming or on-board entertainment platform.






