
Localization: Going local for Global OTT
Localization in OTT covers much more than subtitles and audio dubbing. Learn what key information should be localized in this article.
The increase of foreign-language series in mainstream streaming platforms reflects how standard reading subtitles has become. According to a 2022 study by GWI, approximately 76% of Gen Z and millennial viewers in the UK and US watch TV shows or films in a foreign language. In contrast, the percentage drops to 56% among Gen X and baby boomers audiences. The blockbuster popularity of shows such as “Squid Games”, “Tehran”, and “Babylon Berlin” has led streaming platforms to face the challenge of localizing content and its implications at a database level.
An overabundance of video platforms has made audiences very critical while choosing services. This has increased the pressure on OTT providers to provide excellent value. Since the content library still is the top aspect that audiences evaluate, localization enables services to offer and recommend international content that local audiences might also enjoy. In addition, due to the 2023 writers' strike, many US services are now turning for the first time to license international content, in order to keep providing fresh content to their audiences.
According to the 2023 State of Content Protection report OTT providers plan to increase their original productions in the next three years. Keeping in mind the intense investment that original content requires, it makes sense for businesses to localize these video contents for other markets as well.

What is localization?
Basically, it is the process of making the content suitable for a particular region, done mainly by adding language subtitles and audio translations.
However, from the perspective of OTT, localization encompasses much more than just subtitles and audio dubbing. Metadata associated with the content needs to be localized, which is critical to facilitate its search and discovery in foreign markets. The localization process involves many stakeholders, such as LSPs (Language Service Providers), third-party audio translation studios, content editors, and reviewers.
In addition, OTT providers have to comply with local regulations and keep cultural sensitivity in mind. For example, in certain regions, the content needs to comply with strict rules against nudity and profanity, which entails editing video, image, thumbnail, audio, and subtitle content. Thus, localization is a more extensive process that goes beyond translation.
While translation is limited to converting text from one language to another, localization involves adapting a product or service to suit a specific country or region’s cultural, social, and non-textual elements. Some examples of information that can be localized include date and time formats, promotional images, currencies for SVOD services ($, £, or €), American vs. British English words (elevator vs. lift, Santa Claus vs. Father Christmas, etc.).
Localization aims to facilitate editorial productivity by easing the management of editorial content across different languages and countries. Through a publishing mechanism, both the entity data and its corresponding translation are sent to the end-user service. This process should always include a review mechanism to ensure that every version of an original asset is correctly localized.
While every field of a system could be localized, some items are more critical than others, which are listed below.
| Item | Data Type |
|---|---|
Title |
string |
Description |
string |
Tags |
string array |
Minimum age |
integer |
Maximum age |
integer |
Price (currency) |
decimal |
Categories |
enum (string) |
Rating |
enum (string) |
Premiere Date |
Date / Time |
How does a localization service work?
Since a localization service deals with many types of data, called localizable entities. A localizable entity can consist of one or more fields capable of being localized, and these fields can have different data types, such as strings or arrays of strings. Essentially, any entity within other services that possess textual information attached to it, such as entity metadata (title, description, cast, etc.) or asset metadata (title, description, etc.), can be considered a localizable entity.
Every localized version of a service is known as a locale, and should define (at the very least) the following fields:
| Field name | Type | Description |
|---|---|---|
language_tag |
string |
The language tag is created from valid sub-tags or any other value. |
title |
string |
Descriptive title |
is_default |
boolean |
One language tag is the default one and cannot be changed once it was defined. It must be the first locale that is created - non-default locales can only be created after. |
fallback_language_tag |
A reference to another language_tag that should be used as a fallback in case some parts of the content were not localized yet. |
For translation purposes, most services work by referring to a dictionary/object and then doing a simple string translation assigned to a specific language. The original and its translation are fully independent, and the number of items in a string can differ between languages. We can see an example of this below.
| Original Title | Titles in Foreign Language |
|---|---|
Harry Potter and the Philosopher’s Stone (UK-English) |
Harry Potter and the Sorcerer’s Stone (US-English)
|
Ideally, backend services should establish the localizable fields within their entities and transmit the entity data to the Localization Service. Editors can then carry out translations or localization for each field, with the optional integration of automatic translation applications.
Localization tasks should be integrated into the end-use service or the client application. Examples include the calculation of distance units (like kilometers to miles, or km/h to mph), or currency conversions based on the current exchange rate. In some cases, unit conversions may result in a numerical value, such as 29.3%, which might not be aesthetically pleasing, and an editor can choose to rewrite it as "almost 30%".
Date and number formatting should be handled by the client application itself, where the actual value remains constant regardless of the locale. It is common for end-users to prefer a general language (e.g., English) while desiring the date and number formats to follow their main language (e.g., French). If the actual value changes, such as different release dates for a movie or computer game across countries, the value should be localized accordingly. However, the formatting of that value is typically left to the discretion of the client application.
How to localize
Creating a localized version of a streaming service is a process that affects both the business and development sides of a company. From the non-tech side, it is necessary to select the regions, curate the localized library, translate content, ensure legal compliance, and edit the content itself.
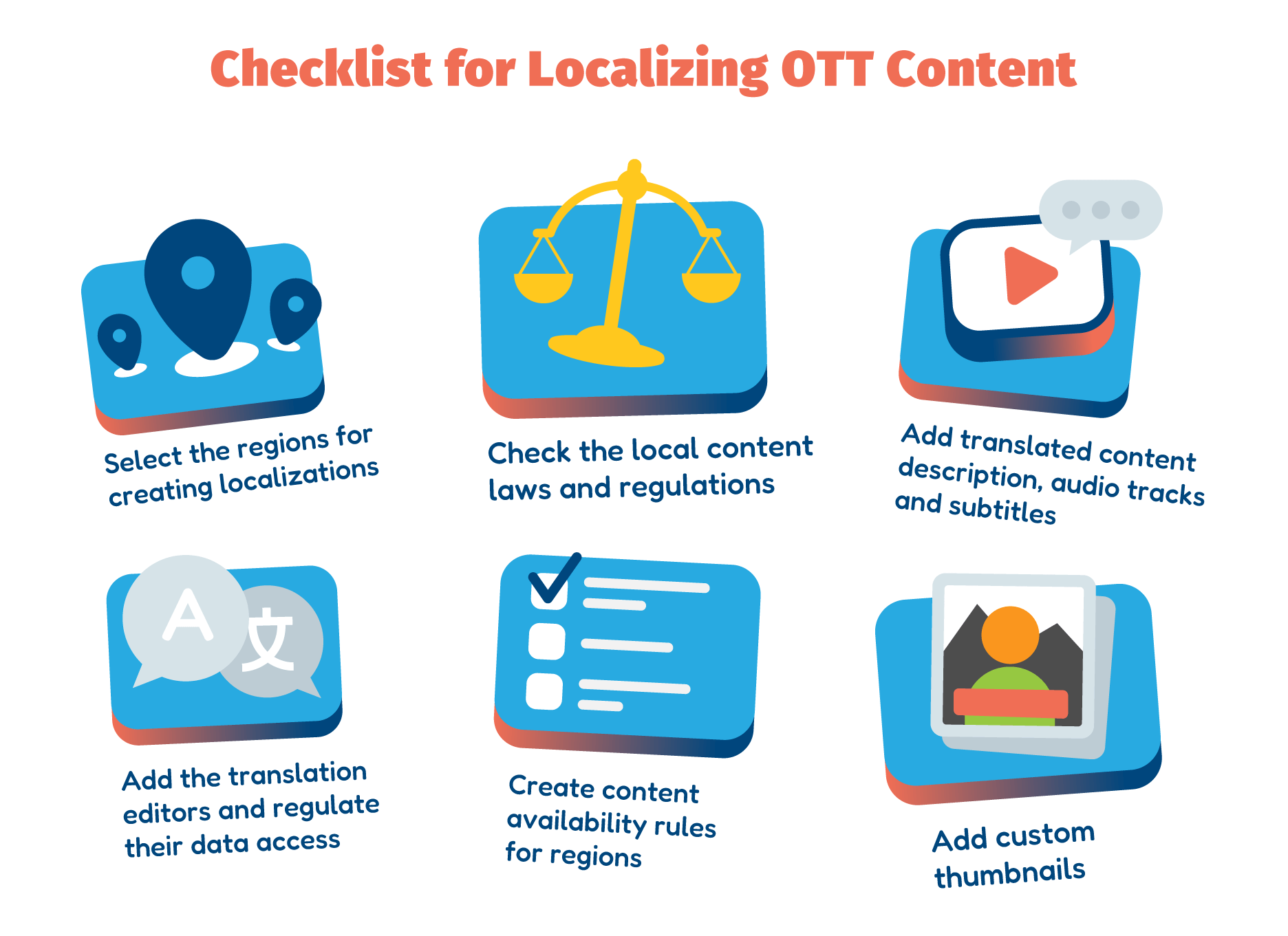
From the backend side, it is necessary to fulfill the following tasks:
-
Establishing end-to-end workflows, in order to manage a massive number of assets including metadata, content targeting, etc.
-
Setting up content access restrictions, to adhere to local policies, and limit the geographic region, devices, and ages that have access to the localized content while also keeping in mind the access needs of traveling viewers.
-
Assigning roles and instances, since the content management and localization process involves a variety of experts, ranging from engineers to editors to translators and reviewers. The solution must provide each user, whether internal or third-party, with a separate dashboard, customized for their specific roles and data access policies.
-
Creating integrations, in order to communicate the backend with AI-powered tools that ingest metadata and automatically generate an enriched version that includes the translation to numerous languages.
How to identify languages within a localization workflow
One aspect of localization is translation, which entails converting a source text into multiple languages, such as English, German, or French. This level of granularity typically suffices for many backends. However, one language can vary in spelling (localization vs. localisation) and vocabulary (elevator vs. lift) depending on the region it is spoken. Variations can also be observed in the character set or script used, as it happens with simplified and traditional Chinese or Latin and Arabic script in Azerbaijani.
There are established standards to address these issues and serve precise language specifications to the user of a streaming service. The current standard for language identification is IETF BCP 47, which combines IETF RFC 5646 and RFC 4647. This specification, known as a language tag, defines a format to identify different languages with a higher level of granularity by combining multiple subtags:
Primary language subtag (language)
The primary language subtag is the first in a language tag and cannot be omitted. Its codes correspond to ISO 639 language codes. Ex. en, fr, de.
Extended language subtags (extlang)
Used for very fine-grained variations of a language. An extlang is used for specific languages (ar, kok, ms, sw, uz, and zh or the sign language sgn). Example: zh-cmn-Hans-CN (Chinese, Mandarin, Simplified script, as used in China)
Script subtags (script)
This subtag specifies the script used to write a language such as Latin, Cyrillic, and simplified Chinese. Its structure corresponds to ISO 15924 script codes. Examples: zh-Hans (simplified Chinese), zh-Hant (traditional Chinese), az-Latn (Azerbaijani, written in Latin script), and az-Cyrl (Azerbaijani, written in Cyrillic script)
Region subtags (region)
Region subtags identify a particular region of the world. There are two types of this subtag: 2-letter codes and 3-digit codes. The latter identifies global regions, rather than specific countries. For example, es-ES means Spanish as spoken in Spain, whereas es-419 means Spanish as spoken in Latin America.
Some final words on localization
The growing presence of foreign-language series on mainstream streaming platforms is proof of the widespread acceptance of subtitles. This trend presents streaming platforms with the complex task of localizing content to cater to the diverse preferences of their users. Media asset management across different languages and countries is possible, but streaming platforms need to properly integrate localization processes into their workflows.






