
What is video encoding: from compressing data to protecting content
Video encoding is the action of compressing video data, but how was it invented, and why now is it used to protect content? Axinom explains.
Video encoding is the process that optimizes the data of video files for various apps, websites, smartphones, TVs, and other devices. Therefore, video encoding is a critical issue developers face while building and maintaining a FAST channel, OTT, or VOD platform. This article will summarize the history of codecs and how they are now the first step in protecting content with a DRM service.
What is video encoding?
Video encoding is a type of data compression that reduces the number of bits used to represent a video of an image. Data and image scientists have developed several algorithms to optimize this compression, known as codecs. The player decodes the compressed data according to the algorithmic rules of the codec and displays the image in a similar quality to the uncompressed video.
The files produced by a codec are a combination of a video codec and a container. The codec produces a bitstream, which is then packaged into a file container by a packaging service. The container is a wrapper file used to store the video information in a single data file, which the codec can decode since it contains the algorithm that encoded the video in the first place. There are many combinations of codecs and containers, as seen below.
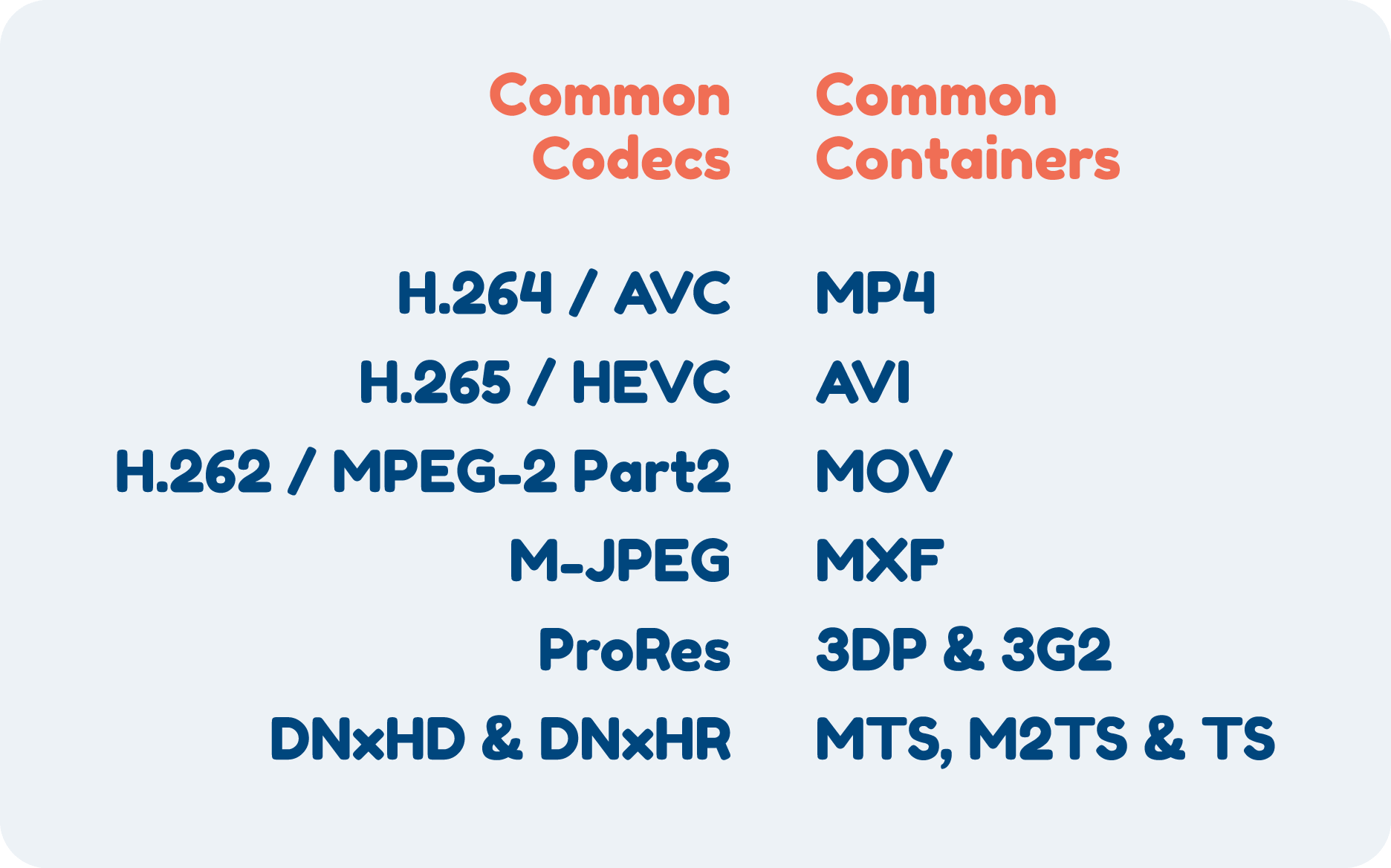
Common video codecs and containers combinations.
The history of codecs
Video compression is an almost mainstream topic thanks to the rise of content and streaming platforms such as Netflix, Twitch, and Youtube. Although it seems quite a modern subject, the origins of video codecs go back almost 100 years ago. In 1929, researcher Ray Davis Kell obtained a British Patent for a revolutionary broadcasting concept for transmitting only different successive keyframes of video. By doing so, fewer keyframes needed to be sent, thus reducing the workload on the frequency employed to broadcast the image.
Although it was hypothetically possible, it took almost 25 years for a technical breakthrough in compression to happen. B.M. Oliver and C.W. Harrison discovered in 1952 that it was possible to use differential pulse-code modulation (DPCM) to reconstruct an image using sample image values and then calculate the future value of those samples. In the following years, more algorithms were proposed and used to reduce image size. The first successful video compression algorithm, Discrete Cosine Transform (DCT), was developed in 1973 by Nasir Ahmed, T. Natarajan, and K. R. Rao. This process splits images into different frequencies, saving only the ones needed to reconstruct the image. Over the following years, scientists worked to make the DCT algorithm faster, which led to it becoming the industry standard.
H.120, the first digital compression algorithm, was introduced in 1984. While great at compressing independent images, it lacked quality stability from one keyframe to another and became primarily used in video conferencing. Four years later, the H.261 codec was introduced and quickly became a commercial success. This codec used a block-based video coding which is still used by many algorithms nowadays, including MPEG-1 Part 2, H.262/MPEG-2 Part 2, H.263 MPEG-4 Part 2, H.264/MPEG-4 Part 10, and HEVC.
Researchers from the Moving Pictures Expert Group introduced the MPEG-1 algorithm in 1993. This codec offered a variety of compressions for VHS raw video data, audio, and metadata for digital cable, satellite TV, and video CDs. To this day, MPEG-1 is a popular codec used to compress audio files and create MP3s.
In 1994, the MPEG-2 codec was introduced for broadcasting networks using NTSC, PAL, and SECAM. The MPEG-2 algorithm reduces data size by creating interlaced video, dividing each keyframe into two fields of horizontal lines; one includes odd-numbered lines, the other even ones. Each keyframe alternates the field of lines they keep, and the final video is created by adding the lines of subsequent keyframes, as seen below.
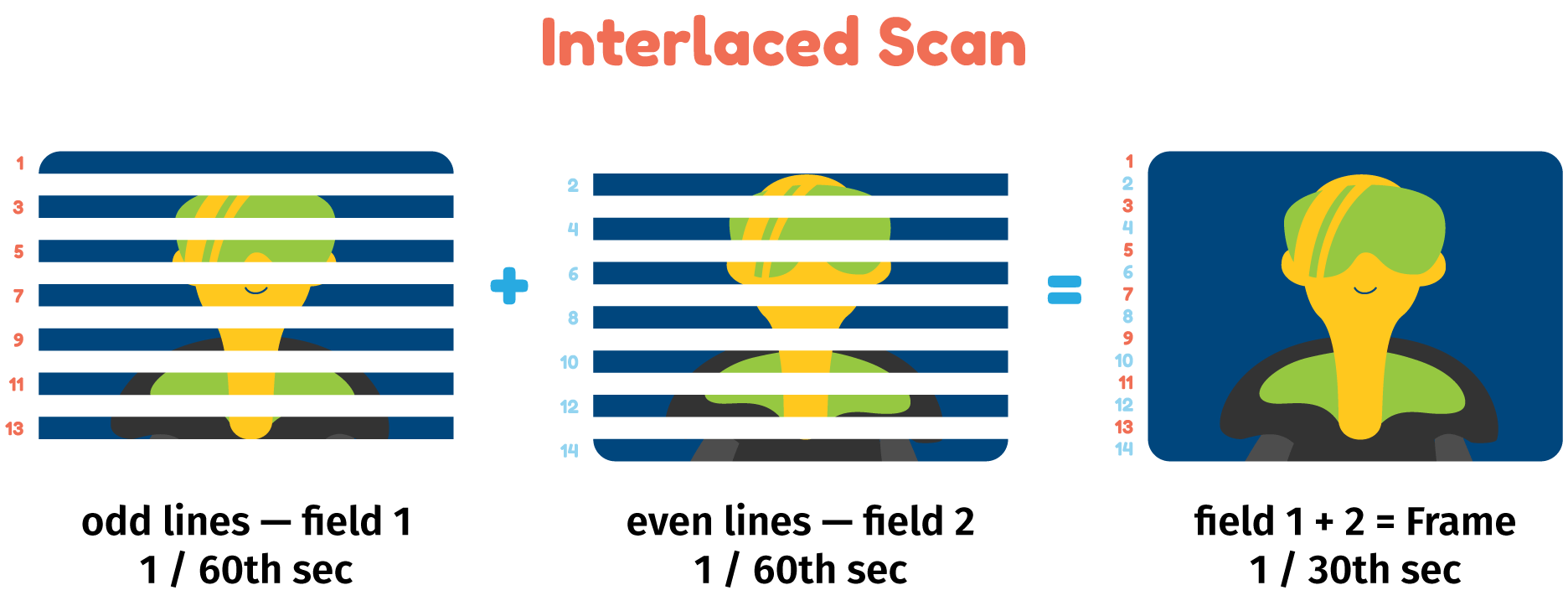
How interlaced scan works.
In addition to interlacing, MPEG-2 introduced chroma subsampling, which encodes video using less color information while keeping the brightness data. Since humans perceive brightness better than color, this subsampling allows for decreasing the file size without being noticeable to the human eye.
The most popular encoding codecs today
In the latter half of the 1990s, scientists focused on improving the algorithms used in video conferencing and media. It was until 2003 that Advanced Video Coding, or H.264/MPEG-4 AVC, was introduced and quickly became the standard across multiple browsers, smart devices, and networks. This code compresses video without losing data (known as lossless compression) and uses block-oriented, motion-compensated integer-DCT coding in a very efficient and fast algorithm. By 2019, 91% of video industry professionals used this codec.

High-Efficiency Video Coding (HEVC), also known as H.265 and MPEG-H Part 2, was released in 2013. Although HEVC produces up to 50% better data compression than its predecessor, licensing fees thwarted the adoption of this codec. Due to this, the Alliance for Open Source Media released the AOMedia Video 1 (AV1) in 2018. This codec offers custom coding and compresses data up to 50% more efficiently over H.264. Some companies currently using AV1 to encode video content are Netflix, Twitch, and YouTube.
From encoding to DRM protection
Once the video data is encoded, you can choose between sending it straight to the packaging process or to another service to protect it from piracy. This service is known as DRM, or Digital Rights Management, with some significant players being Widevine, PlayReady, and FairPlay. All these DRM technologies use AES encryption with a 128-bit Content Key to include information in the video data stream that regulates user access. Due to this additional processing, encoding and protecting video for streaming has become a long-running activity that can take minutes and even hours, depending on the file size, the codec used for image processing, and the DRM service employed to secure the file.

The DRM stage of the process starts with the encoding service validating the request from the user (via JSON). It then obtains the necessary keys from the DRM service and allocates them to the stream. It is currently a best practice to use independent Content Keys for streams with different video quality, according to the usage policies assigned to said streams by a License Service.
As you can see, encoding has changed from being a single process to being the first step in preparing video files for online distribution. In upcoming articles, we will describe in more detail the role of the encoding process in streaming platforms, best practices in video processing, and how encoding works together with other platform components such as DRM services.






